
Predicting Football Matches Using Poisson Distribution ⚽
In this project, I use the Poisson Distribution to predict football matches based upon historical data.
Introduction
In this project, I delve into the world of sports predictions by developing a match outcome predictor using Python. This system leverages statistical models—specifically, the Poisson distribution—to estimate the probabilities of different match results based on historical performance data. By examining past games, the model assesses team strengths and predicts likely scores for future matches.
The goal of this system isn’t just about predicting who will win or lose, but rather to provide a detailed probability of various outcomes, offering insights that can be invaluable for sports journalists, betting enthusiasts, and fans alike. This approach highlights the transformative power of machine learning and data science in the sports industry, where data-driven decisions are becoming the norm.
Sourcing the Data: 2018-2019 Premier League Data to April 2024
Football data sets are widely available, through Kaggle, personal data collection or various sport analytics websites. I collected my data from ‘Football-Data.co.uk‘, where I primarily focused on the English Premier League and the last 5 seasons of it. The data was easily downloadble in .CSV formats, and through the use of the pandas library, concatenating these .CSVs was an easy task. I then had one .CSV file called ‘historical_data.csv’ which I could then load into Python for further preprocessing.
Process Overview
To develop a match outcome predictor using the Poisson distribution, we follow a structured approach, breaking down the complex processes into manageable steps. Here’s an overview:
- Data Preparation: The first step involves gathering and preparing historical match data for analysis. This includes loading the dataset into a Python environment, exploring its structure, and cleaning the data to remove any inconsistencies or missing values.
- Poisson Model Setup: The core of the project lies in setting up the Poisson distribution model. This model predicts the number of goals each team might score in a match based on their past performance. The setup includes defining the model’s parameters and fitting it to historical match data.
- Match Outcome Estimation: Using the Poisson model, the probabilities of different outcomes for upcoming matches are calculated. These outcomes include predicting the number of goals each team is likely to score in a match.
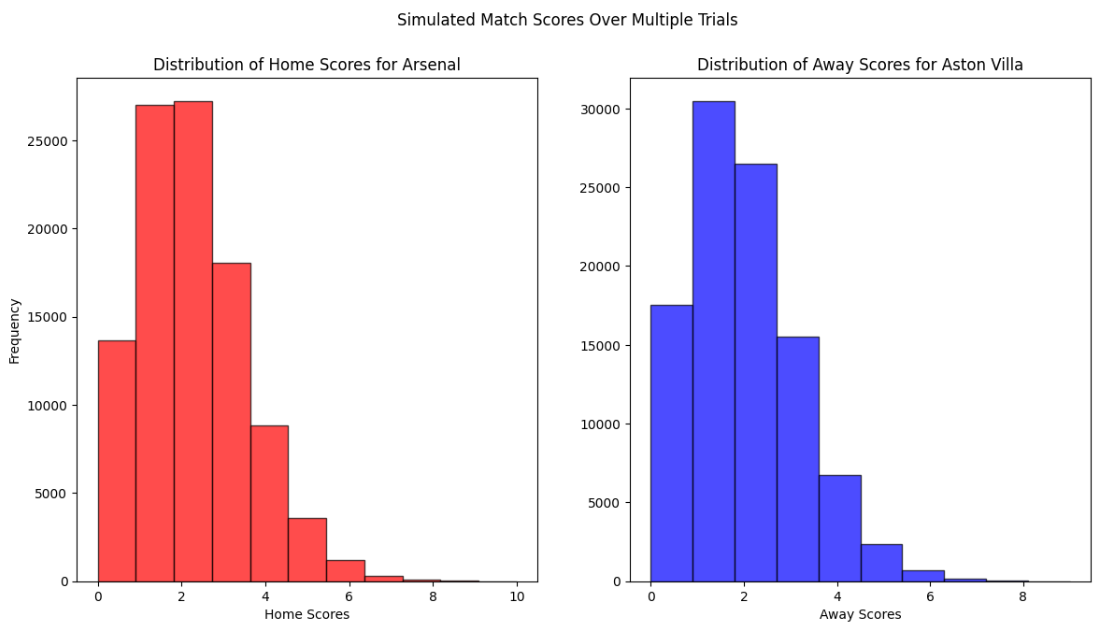
- Results Visualisation: The predictions are visualised using graphs that display the analysis of the Poisson model. These visualisations help in presenting the model’s predictions in an understandable way, making it easier to interpret the likelihood of various outcomes.
Poisson Distribution
The Poisson distribution is a statistical tool used to model the number of times an event happens in a fixed interval of time or space. In simple terms, it helps us understand how likely it is for something to happen a certain number of times within a given period.
Here is the Poisson distribution formula:
\[ P(k; \lambda) = \frac{\lambda^k e^{-\lambda}}{k!} \]
Here is an explanation of the variables in the Poisson distribution formula:
\( \lambda \) (lambda) is the average number of events in the interval (e.g., average goals per match).
\( k \) is the number of events (e.g., number of goals).
\( e \) is the base of the natural logarithm, approximately equal to 2.71828.
\( k! \) (k factorial) is the product of all positive integers up to \( k \).
In football, the Poisson distribution can be used to predict the number of goals a team might score in a match. For example, if Team A has historically scored an average of 1.5 goals per match, we can use the Poisson distribution to calculate the probability of different goal outcomes in an upcoming match.
Suppose we want to find the probability that Team A scores exactly 2 goals. We would set \( \lambda = 1.5 \) and \( k = 2 \):
\[ P(2; 1.5) = \frac{1.5^2 e^{-1.5}}{2!} \]
This calculation will give us the probability of Team A scoring exactly 2 goals based on their historical average. By modeling the goal-scoring capabilities of both teams using such calculations, we can predict the likely outcomes of their matchups, which is particularly useful for sports analytics, betting industries, and fans looking to understand the dynamics of forthcoming games.
The Code
Feel free to view my Poisson model to predict football matches below. Play around with it, change the parameters and feel free to add improvements. It’s a fun little project to play around with to see how accurate the predictions can be. You just need to modify these parameters. (100,000 trials might be excessive 🤣)

Future Improvements
There’s a lot that can be added to this project. Here are a few I’ve thought of:
- We have time data, therefore it is possible to create a ‘win probability by season’ to see how teams have strengthened or weakened per season.
- Adding more data? Usually in projects adding more data is always valuable and can make the models more accurate. However, would adding data from 15 years ago improve the model considering how much football has changed?
- Use of a more complex model such as a Dixon-Coles model will most likely lead to a more accurate model.