Amar Ladva
Data Scientist
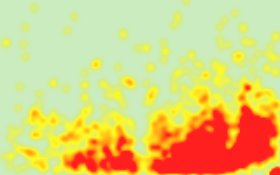
The initial phase of this research project focused on data collection, with the objective of acquiring heatmap data for football players. Sofascore emerged as a prime source, being among the few football data platforms to offer such information. The challenge then shifted to scraping this data effectively to create a dataset substantial enough for accurate model training.
To ensure a sufficiently large and diverse dataset, I opted to collect heatmap data from players across the top 5 European football leagues (



 ). This approach was projected to yield data for approximately 2000 players, a figure considered adequate for the purposes of this study, though with room for expansion in future research. The data scraping was executed using Selenium, saving the heatmaps in a straightforward format named after the convention ‘firstname_lastname.png‘
). This approach was projected to yield data for approximately 2000 players, a figure considered adequate for the purposes of this study, though with room for expansion in future research. The data scraping was executed using Selenium, saving the heatmaps in a straightforward format named after the convention ‘firstname_lastname.png‘